May 6, 2016

by Helen Gregg, University of Chicago Magazine
Critic James Baldwin once wrote that sentimentality is “the ostentatious parading of excessive and spurious emotion” and “the mark of dishonesty.” He’s not alone—for generations reviewers and critics have used emotive writing to separate mass-market pulp from real literature, says Richard Jean So, assistant professor of English. But can sentimentality really serve as a litmus test for the lowbrow?
“I don’t want to say James Baldwin is wrong,” says So. “But there’s a different way of looking at the question.”
For years So has been using text mining, natural language processing, and other computer-based techniques to gain more quantitative perspectives on literature and culture. The digital humanities, as the burgeoning field is known, leverages advances in computer science and the mass digitization of literary texts to “look at big patterns” across many works, says So, and offers insights “in a new way, more at scale, and perhaps more convincingly.”
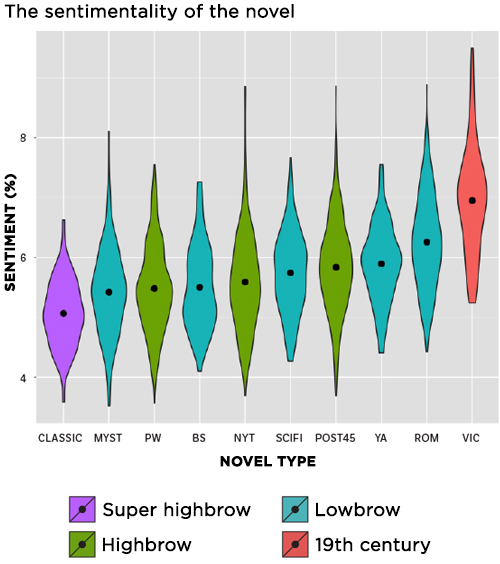
To compare the sentimentality of different types of novels, So and his collaborator Andrew Piper of McGill University used a computer program to count the instances of emotionally charged words like abominable, obscene, courageous, and rapturous in roughly 2,000 digitized books.
The graph of their results shows the average percentage of sentimental words across the different classifications and genres of novels. By far the most maudlin were the Victorian-era novels, which contain, on average, about seven and a half more sentimental words per page than contemporary prize-winning fiction (PW).
While books in some popular genres like romance or young adult were found to have a higher concentration of sentimental words than prize-winning novels or those reviewed in the New York Times, mysteries and best sellers (BS) tended to be on par, sentimentality-wise, with those books considered more literary. Of the 400 postwar novels (POST45) studied, the 60 most canonical works (CLASSIC)—by authors like Toni Morrison and Vladimir Nabokov—were found to be the least sentimental, though So and Piper note that this is largely because of the classics’ disproportionate lack of positive words.
These results indicate that preconceived notions may have been obscuring a more complex picture of the role of sentimentality in novels, says So, and may vindicate emotive writing. The Research Computing Center helped So develop data-mining tools for his analysis, as well as providing computational and consulting support.
He and Piper recently analyzed whether novels by writers with MFAs varied significantly in content or style from other writers’ novels. (Their conclusion: not really.) They’re also developing projects on American culture more generally, evaluating the impact of Buzzfeed-style writing on traditional journalistic discourse and measuring white appropriation of black lyrics in rock and pop music from the 1950s to today. So cotaught a course on cultural analytics last quarter and regularly hosts forums and lectures on the digital humanities with another frequent collaborator, Hoyt Long, associate professor of Japanese literature at UChicago.
Using computers to analyze art is not without controversy in academia, but So, who trained as a more traditional close reader, is adamant that computer-based approaches will never replace other forms of literary analysis. The digital humanities, he says, is about “taking the core humanistic values and questions and putting them into dialogue with new methods” from other disciplines to uncover new knowledge. “A computer is, in some ways, a very sophisticated, subtle reader of literature.”
-See the original version of this article at http://mag.uchicago.edu/arts-humanities/novel-data.