
The OCHRE database supports many projects, including the Chicago Hittite Dictionary. Original image of Hittite inscription courtesy of the Oriental Institute of the University of Chicago. Photo illustration by Ricardo Aguilera, Research Computing Center.
by Benjamin Recchie
Good archaeology requires a lot more than sticking a spade in the ground and seeing what turns up—it requires carefully captured and curated data. Lots of data. In fact, managing the enormous quantity of information—including, but not limited to, ceramics, bones, rocks, dirt, pictures, descriptions, measurements, and interpretations by experts—that comes out of an archaeological dig is a major challenge to researchers.
This is the problem that birthed OCHRE (the Online Cultural and Historical Research Environment), explains research database specialist Sandra Schloen, one of the project’s cofounders at the Oriental Institute of the University of Chicago. Prior to OCHRE, archaeologists had to make do with unwieldy spreadsheets and other repurposed software developed for the business world. “We looked at the kind of data that needed to be captured and came up with a new way of representing it,” Schloen says, one which encapsulated all the variety of things archaeologists could find. They ended up with a generic model that also happened to have wide applicability to fields beyond archaeology. And then, she says, “OCHRE just grew.”
The next field to use OCHRE was philology, the study of language in written historical sources. Analogous to the way in which archaeologists capture the context of artifacts within the context of an excavation, the OCHRE data model allows for observations on a wide range of textual data, from the minute to the broad, from the identity of every sign or letter in a text to varying interpretations and translations. After that, OCHRE started to be applied to fields like biology and history; it’s particularly well suited to historical projects involving network analysis of people and places, says Miller Prosser, another research database specialist with the OCHRE Data Service—the movement of commodities, coins, or even abstract concepts such as ideas. “If you can observe something about anything, it can be captured in OCHRE,” he says. (He exaggerates only slightly.)
When the Research Computing Center started in 2013, the developers of OCHRE were quick to make use of it. (“I don't think we were the first allocation, but we were one of the first,” says Prosser.) OCHRE’s computational needs weren’t great—they’ve never needed Midway’s high-performance computing, for instance—nor have their storage needs been as large as some other RCC users. But “we’re big data for the humanities,” says Schloen, and RCC’s resources helped them bring computational approaches to data that isn’t usually treated computationally. This included server space, help with transferring large files, and helping them develop new tools for the database. This last item is part of CRESCAT (Computational Research Ecosystem for Scientific Collaboration on Ancient Topics) a cyberinfrastructure project funded by the National Science Foundation. Since OCHRE has proven itself so useful in organizing hierarchical data, CRESCAT will provide the tools to interrogate the database about the relationships between entities.
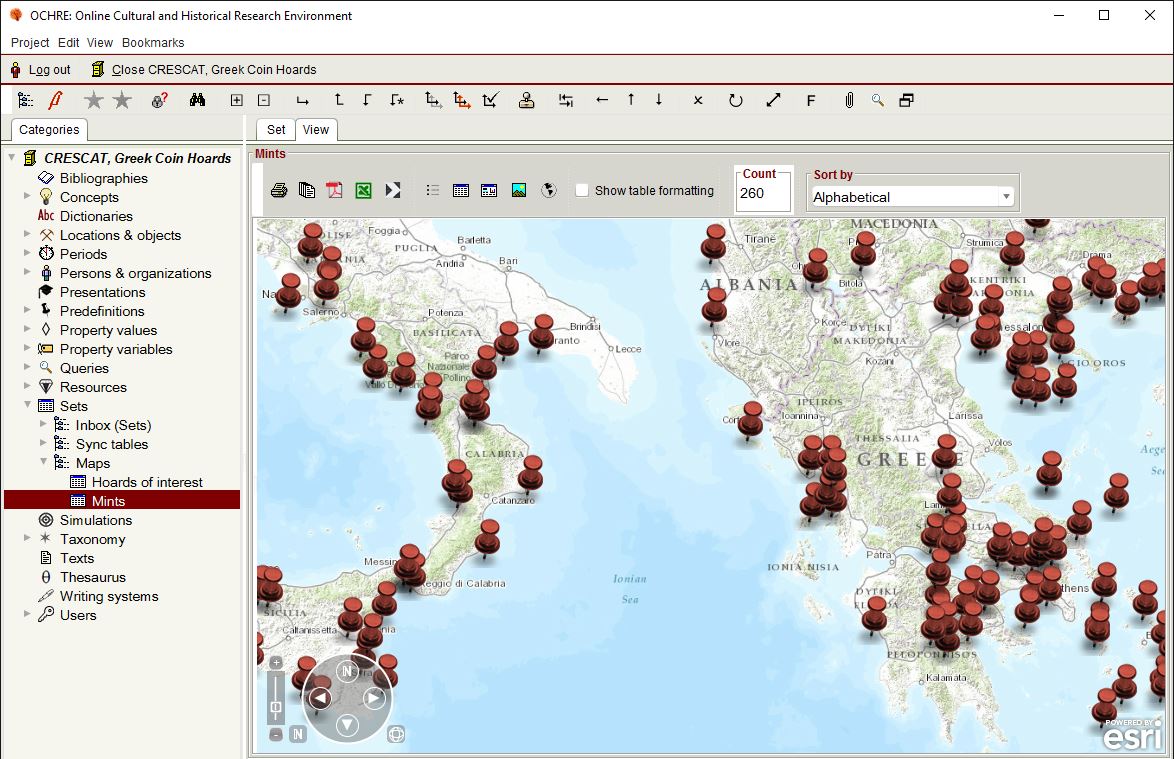
A screenshot of CRESCAT, showing data on ancient Greek coin hoards.
Once such project is studying Greek coin hoards—caches of coins buried for safekeeping in antiquity but, for whatever reason, never retrieved. Thousands of such coin hoards have been discovered around the Mediterranean world, explains Prosser, anywhere there was a Greek or Roman influence. From the dates the coins were minted, the cities they were minted in, and the location the hoard was found, a complex web of relationships unfurls. CRESCAT will provide the tools necessary to make sense of those relationships, as well as in two other projects: medieval inscriptions in India and a paleobiology project that studies microscopic animals called bryozoans.
When preparing for CRESCAT, Schloen and Prosser met with RCC student worker Matt Best and outlined what tools OCHRE would need to study network relationships more effectively. Best, a graduate student in computational neuroscience, then gave them a presentation on how neurons in animal brains control the chewing and swallowing of food; the tools involved to study the networks in both fields rely on similar principles. Schloen still marvels at it. “Who would have thought there was common ground between us?”